原理
中文网页的编码方式主要有 2 种,GB2312 和 UTF-8 。在 GB2312 方式中,一个汉字占用 2 个字节,而 UTF-8 方式中,一个汉字占用 3 个字节。如下图,当我们将“一”这个汉字分别用 GB2312 和 UTF-8 方式储存的时候,以 16 进制方式来看,它们的内容是不一样的。
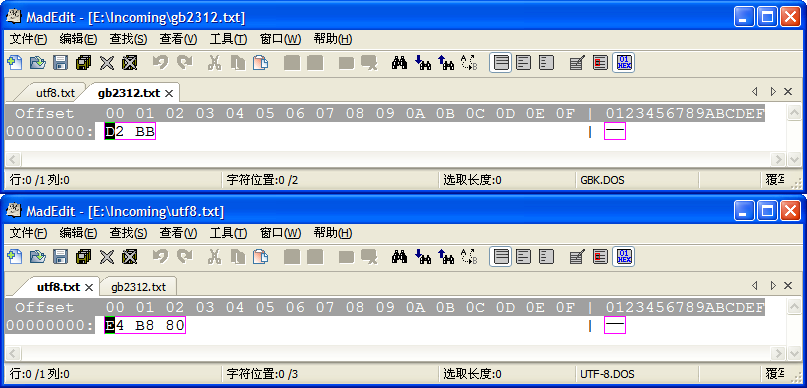
在 Proxomitron 的配置文件中,一个汉字也是占用 2 个字节,所以我们可以直接过滤 GB2312 编码网页中的中文;另一方面,我们不能用 2 个字节去匹配 3 个字节,所以不能直接过滤 UTF-8 编码网页中的中文。
匹配
尽管 Proxomitron 的帮助文件没有提到,但它实际上提供了以 16 进制方式按字节匹配的能力,符号为 [%xx]。
以上图为例,如果要匹配 UTF-8 编码的“一”字,表达式为:
[%e4][%b8][%80]
替换
显然,我们无法通过 Proxomitron 在 UTF-8 编码的网页中插入以 3 个字节为存储单位的汉字,但我们可以通过 character entity 的方式来达到我们的目的。关于 character entity 的知识,请自行 Google 。
实例
以 www.google.cn 为例,以其中的“高级搜索”字符串为目标。
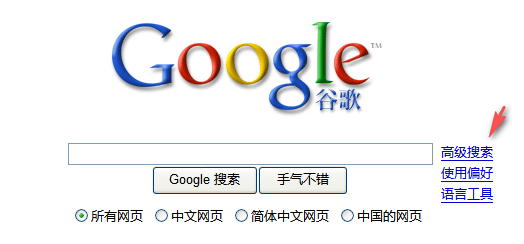
通过 16 进制工具,我们可以看到其 16 进制内容为:
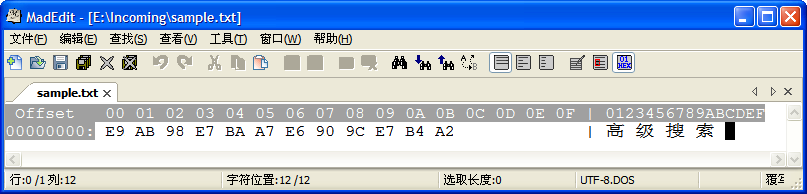
相应的,匹配表达式应该写为:
[%E9][%AB][%98][%E7][%BA][%A7][%E6][%90][%9C][%E7][%B4][%A2]
本例中,我打算将其替换为“不做恶”,其 character entity 格式为:
不做恶
最终的规则如下:
[Patterns]
Name = "utf-8 demo"
Active = TRUE
URL = "$TYPE(htm)www.google.cn/"
Limit = 20
Match = "[%E9][%AB][%98][%E7][%BA][%A7][%E6][%90][%9C][%E7][%B4][%A2]"
Replace = "不做恶"
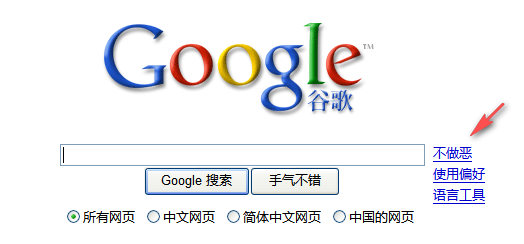
过滤效果如下:
在线转换工具
我写了一个小工具,可以方便地将 UTF-8 字符串转换成 Proxomitron 的 Match 和 Replace 格式。
链接: 相关讨论